
[IT조선 유진상] 고성능컴퓨팅(HPC) 시장에서 GPU와 코프로세서 등을 활용한 보조 프로세서의 경쟁이 본격화되고 있다. GPU를 탑재한 HPC들이 대세를 이루는 가운데 인텔은 제온 파이(Xeon Phi) 코프로세서(액셀러레이터)를 앞세우는 한편, 인피니밴드의 대상으로 옴니패스 패브릭 인터커텍트 기술로 중무장하고 반격을 꾀하고 나섰다.
27일 관련업계에 따르면, 전 세계 HPC시장에서 성능과 전력효율을 높이기 위한 방안으로 보조 프로세서의 탑재가 늘고 있다.
실제 지난해 11월 발표된 슈퍼컴 톱500에 따르면, 시스템 성능향상을 위해 CPU에 GPU(Graphics Processing Unit)를 탑재하는 경우가 많아지고 있다. 지난 2013년 62개 시스템에 적용되던 코프로세서 기술 사용 시스템은 2014년 75개로 늘어났다. 이중 50개 시스템은 GPU를 사용하고 있으며, 인텔의 코프로세서는 25개였다.
또 전 세계 슈퍼컴퓨터 중 가장 빠른 것으로 평가된 중국의 텐허와 7위를 기록한 스탬피드는 계산 속도를 빠르게 하기 위해 인텔 제온 코프로세서를 사용하고 있다. 또 두 번째로 빠른 슈퍼컴인 타이탄과 6위를 기록한 피즈의 경우는 GPU를 사용하고 있다.
앞서 슈퍼컴퓨터 순위에서 확인할 수 있듯이 현재까지는 시장에서 GPU를 탑재한 컴퓨팅이 보다 우위를 차지하고 있는 듯한 모습이다. GPU컴퓨팅이란 CPU보다 연산성능이 탁월한 GPU를 활용해 주로 일반적인 연산에 활용하는 것을 의미한다. 기존 HPC가 CPU로만 연산업무를 처리했지만 GPU를 탑재해 속도 개선과 소비전력까지 줄일 수 있는 효과가 있다는 것이 GPU 컴퓨팅 진영의 주장이다.
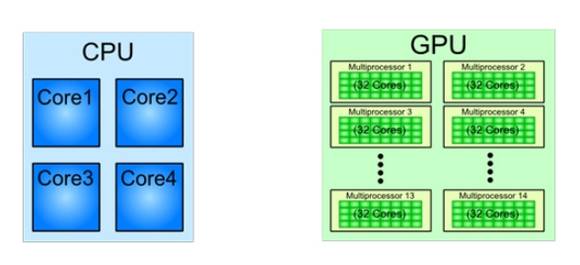
하지만 GPU 기반 HPC는 병렬 워크로드 지원 애플리케이션이 많지 않다는 게 단점으로 지적된다. 또 인텔 측은 GPU 기반의 병렬 컴퓨팅이 복잡한 구조를 가지고 있다고 주장해 왔다. 병렬 컴퓨팅을 수행하기 위해선 기존 코드에 일부 수정이 필요한데, 이 과정에서 복잡하고 효율성이 떨어진다는 것이다.
찰리 위슈파드 인텔 데이터센터 그룹 부사장은 “GPU 프로그래밍이 어렵다는 점은 최대의 단점”이라며 “인텔의 코프로세서 방식이 생산력, 투자 수익 등에서 분명 우위에 있다”고 주장했다.
엔비디아, 신기술 통해 슈퍼컴 대권 노린다
이에 GPU 진영의 대표주자인 엔비디아는 GPU와 그 주변 기기들에 큰 변화를 예고하고 나섰다. 우선 NV링크(Link)를 공개했다. NV링크는 PCIe를 사용하는 현재의 GPU와 CPU간의 데이터 병목 현상을 해결하기 위한 기술로 최대 12배의 넓은 대역폭을 확보할 수 있다. 현재의 16GB/s에 불과한 CPU/GPU간 메모리 대역폭은 분명 심각한 병목현상을 낳고 있지만 NV링크를 통해 80GB/s 이상의 대역폭으로 문제를 해결할 수 있을 것으로 기대되고 있다.
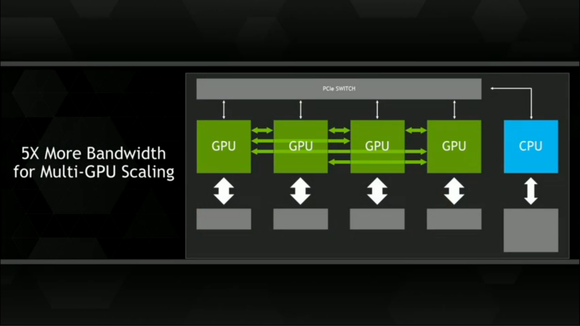
또 다른 기술은 적층메모리(Stacked Memory)다. 적층메모리는 기존의 메모리에 비해 보다 큰 대역폭을 제공하므로 이 역시 메모리 병목 현상을 줄이고 고속 연산을 가능하게 만들어 줄 것으로 평가된다.

특히 엔비디아는 IBM과의 협력을 통해 IBM 차기 CPU인 ‘파워9’과 엔비디아 차기 GPU인 볼타를 사용해 2017년 차기 슈퍼컴퓨터인 시에라(SIERRA)와 서밋(SUMMIT)를 2017년 시장에 선보일 예정이다.
인텔, 2016년을 기대하라
인텔 측의 반격도 만만치 않다. 인텔은 우선 지난해 11월 차세대 인텔 제온 파이 프로세서 ‘나이츠 힐’과 인피니밴드의 대안으로 옴니패스 패브릭 인터커넥트 기술을 선보였다.
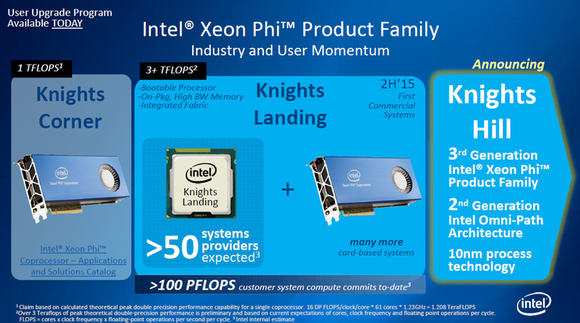
우선 올해 인텔은 ‘나이츠 랜딩’을 시장에 출시할 예정이다. 나이츠 랜딩은 최초로 단일 프로세서에서 배정밀도 연산능력(double precision floating point performance) 기준 3테라플롭스(TFLOPS) 이상의 연산 능력을 갖추고 있다. 14nm 공정에 실버몬트 기반의 x86 코어를 지닌 60개 이상의 병렬 연산 코어를 갖췄다.
나이츠 랜딩은 로스 앨러모스(Los Alamos)와 샌디아 국립연구소(Sandia National Laboratories)가 함께 개발한 슈퍼컴 ‘트리니티(Trinity)’와 미 국립 에너지 연구과학 컴퓨팅센터(NERSC)의 ‘코리(Cori)’ 등에 사용될 예정이다.
또 인텔은 인피니밴드의 대안기술인 옴니패스를 선보였다. 인텔 옴니패스 아키텍처는 48포트 스위치 칩을 사용해 기존의 36포트 인피니밴드에 비해 향상된 포트 집적도와 시스템 확장성을 제공하는 것이 특징이다. 스위치 칩 당 최대 33% 증가된 노드 수를 제공해 필요한 스위치의 수를 감소시킬 수 있고 시스템 설계의 단순화와 인프라 비용 절감 효과를 거둘 수 있다는 것이 인텔 측의 설명이다.
이 밖에도 인텔은 나이츠 랜딩의 후속인 나이츠 힐도 선보일 계획이다. 나이츠 힐은 10nm 프로세서와 2세대 옴니패스 아키텍처를 사용한 3세대 제온파이 프로세서다. 나이츠 힐은 특히 2018년 선보일 180~450 페타플롭스 성능을 갖춘 슈퍼컴퓨터 ‘오로라’에 장착될 것으로 전망되고 있다.
오로라는 인텔 HPC 스케일러블 시스템 프로엠워크와 크레이의 차세대 제품인 샤스타(SHASTA)를 토대로 제작되며 성능만 높은 것이 아니라 에너지 효율도 현 세대 슈퍼컴퓨터보다 6배 이상 높을 것으로 기대되고 있다.

위슈파드 부사장은 “2014년 슈퍼컴퓨터 분야는 이전과 비교해 상대적으로 조용했다”며 오는 2016년 HPC 분야에서 흥미진진한 진척이 있을 것이고 그 중심에 나이츠 랜딩과 나이츠 힐이 있을 것”이라고 강조했다.
국내 슈퍼컴퓨팅 업계 관계자는 “인텔은 마치 과거의 IBM의 모습과 유사하다”며 “다만 가지고 있는 것 만큼의 성과를 내지는 못하고 있다”고 설명했다. 그는 이어 “인텔의 코프로세서와 엔비디아의 GPU 경쟁은 최근 HPC 업계 가장 뜨거운 감자”라며 “양측의 경쟁이 결국 일반 컴퓨터의 발전을 끌고 가는 만큼 의미가 있으며 긍정적인 경쟁”이라고 말했다.