
[IT조선 유진상] “이세돌 9단과 알파고의 바둑 대결은 5:5가 될 것이라고 예상된다."

데미스 하사비스 구글 딥마인드 공동창업자 겸 CEO는 알파고와 이세돌 9단과의 바둑 대결에서 누가 이길지에 대한 취재진의 질문에 대해 이렇게 대답했다. 28일 구글코리아는 서울 강남파이낸스센터 21층 회의실에서 영국의 딥마인드 본사와 연결해 화상회의를 진행했다. 구글의 AI 알파고와 인간의 대결에서 5:0 승리를 거둔 것을 보다 상세히 알리고, 오는 3월 이세돌 9단과 알파고의 대전을 알리기 위함이었다.
하사비스 CEO는 “이세돌 9단을 만나러 한국에 올 것”이라며 “무엇보다도 도전을 받아준 이세돌 9단에게 고맙고, 무척이나 기대된다”고 말했다.
“인간이라면 1000년을 수련한 셈”
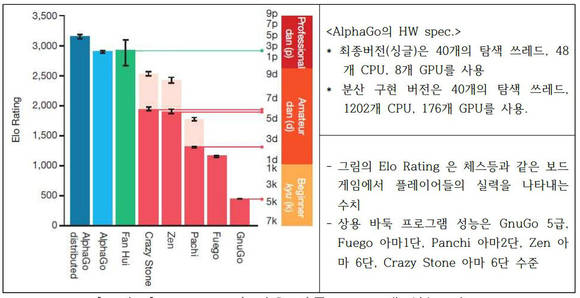
실제 알파고는 실력은 얼마나 될까. 알려진 바로는 알파고의 실력은 KGS기준으로 프로 2~5단 정도의 실력을 갖추고 있다. 이세돌 9단과 비교하면, 급수로는 몇 수 아래다. 다만, 일반적인 상용 바둑 프로그램들과 비교하면 가장 좋은 실력을 갖춘 것으로 평가된다. GnuGO가 5급, Fuego 아마 1단, Panchi 아마 2단, Zen 아마 6단, Crazy Stone 6단 등의 수준이다.
알파고와 기존 바둑 게임 프로그램의 토너먼트 결과는 총 495게임을 치른 결과 494번의 승리를 거둬 99.8%의 승률을 보였다. 또 3점 접바둑 게임의 경우는 크레이지스톤(CrazyStone), 젠(Zen), 파치(Pachi) 등과의 대국에서 각각 77%, 86%, 99%의 승률을 보였다.
이에 대해 하사비드 CEO는 “알파고는 4주간 중단없이 반복적으로 학습을 했다”며 “사람처럼 순차적으로 두는 방식이 아닌 전체적인 수를 보고 익힐 수 있도록 했고 100만 번의 경기를 배우도록 했다”고 설명했다. 한 선수가 일 년에 1000번의 게임을 한다고 했을 때, 알파고는 1000년 동안 바둑을 둔 셈이다.
이렇게 수련을 쌓은 알파고는 공식 경기 5회, 비공식 경기 5회를 치른 결과 공식 경기에서 유럽 바둑챔피온 판후이 프로2단을 5:0으로 완파했다. 비공식 경기에서는 3:2로 승리했다. 모두 중국식 규칙을 따랐으며 비공식 경기에서만 초읽기를 30초의 초속기 방식으로 진행했다.
왜 바둑인가
체스와 퀴즈 게임에서 세계 챔피언을 인공지능이 이기고 있음에도 불구하고 바둑만큼은 사람이 인공지능보다 낫다는 평가가 지배적이다. 때문에 인공지능 기술을 연구하는 측에서는 가장 큰 도전과제로 평가됐다. 이는 바둑이 고전 게임들 중 탐색 범위가 가장 넓고 판의 상황을 평가하는 것이 굉장히 어렵기 때문이다.
체스는 20개에 불과한 경우의 수를 갖고 있을 뿐이다. 또 돌마다 가치가 다르게 부여돼 특정포지션에서 누가 이길지 예측이 가능하다. 하지만 바둑은 돌마다 가치가 모두 같기 때문에 득정 포지션에서 누가 이길지를 예측하기가 불가능하다.
하사비스는 “바둑은 규칙은 단순하지만 심호하고 복잡한 면모를 갖추고 있다”며 “바둑은 지금까지의 어느 게임들보다도 완벽하고 인간이 만들어낸 가장 복잡한 게임”이라고 말했다.
데이비드 실버 딥마인드 리서치 사이언티스트 강화학습 연구 총괄 역시 “바둑의 복잡성은 엄청난 탐색 영역이 필요할 뿐 아니라 바닥의 복잡성을 단순화시키고 그 영역을 축소화하는 등 다양한 기술이 적용돼야만 한다”고 설명했다.
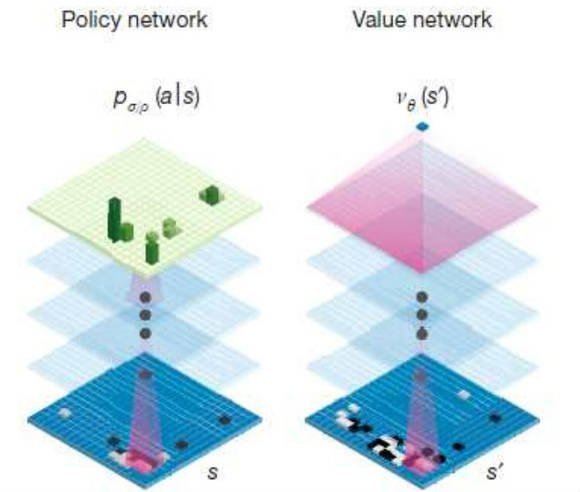
이를 위해 알파고는 딥러닝과 강화학습(Reinforcement Learning), 몬테카를로 트리 탐색(monte Carlo Tree Search) 등의 인공지능과 게임이론의 최신 기술을 적극 활용했다. 또 구글의 HW 인프라를 적극적으로 사용했다.
우선 알파고에는 딥러닝 기법 중 컨벌루션 신경망이 적용됐다. 컨벌루션 신경망은 페이스북에서 얼굴인식에 사용한 것으로 유명해진 딥러닝 기술이다. 입력 이미지를 작은 구역으로 나눠 부분적인 특징을 인식하고 신경망 단계가 깊어지면서 이를 결합해 전체를 인식한다.
김석원 소프트웨어정책연구소 책임연구원은 SPRi 이슈 리포트를 통해 “바둑에서는 사활 문제같은 국지적 패턴이 중요하고 이를 부분적 패턴이 전반적인 형세와 점진적으로 연관되기 때문에 컨벌루션 신경망을 이용하는 것은 적절한 선택”이라고 설명했다.
또 알파고는 지도학습한 신경망끼리 게임을 하고 이긴 쪽으로 가중치를 조정하는 강화학습이 적용됐다. 신경망 적용이 기보를 배워 기보를 둔 사람 수준의 바둑을 목표로 한다면, 강화학습은 기보를 넘어서는 성능을 쌓기 위한 개인 훈련으로 볼 수 있다.
뿐만 아니라 몸테카를로 트리 탐색을 정책망과 결합해 예측이 가능하도록 했다. 다음 수를 찾기 위해 현 상태에서 나와 상대가 모두 동일한 정책망을 가진 것으로 가정하고 여러 번 시뮬레이션을 실행해 가장 높은 빈도로 선택한 수를 택하는 방식이다.
여기에 알파고는 40개의 탐색 쓰레드와 48개의 CPU, 8개의 GPU를 사용했으며, 분산 구현 버전은 40개 탐색 쓰레드, 1202개 CPU, 176개 GPU가 사용됐다.
데이비드 실버 연구총괄은 “정책망은 가장 좋은 수를 찾고 가치망이 가장 성공적인 수를 실행하게 된다”며 “정책망에 3000만 가지의 경우가 입력됐으며, 사람의 움직임을 57%까지 예측할 수 있도록 능력을 키웠다”고 설명했다.
알파고, 딥블루·왓슨과의 차이는?
그럼 알파고는 경쟁사인 IBM의 딥블루와 왓슨과는 어떤 차이가 있을까. 딥블루는 과거 인간과 체스 경기를 치뤄 승리한 것으로 유명해졌으며, 왓슨은 제프리 쇼에서 인간을 상대로 우승을 거머쥐었다.
데이비드 실버 총괄은 “97년 IBM의 딥블루가 체스경기에서 인간을 승리할 수 있었던 것은 20수를 예측하면서 경우의 수를 모두 대입해 진행됐다. 이미 사전에 모든 정보가 입력됐다는 것”이라며 “또 다른 인간과의 대결인 제프리 퀴즈쇼에서 왓슨이 우승한 것은 또 다른 접근법으로 IBM은 당시 특별한 사례를 하나의 DB로 구축했고 질문이 나왔을 때 특정 주제에 대해 집중적으로 검색해 답을 찾은 것”이라고 설명했다.
유진상 기자 jinsang@chosunbiz.com