개발 전문잡지 마이크로소프트웨어의 최신호는 인공지능 개발에 필요한 체크포인트(The Checkpoint of AI)를 다뤘습니다. 데이터 수집, 정제, 학습법, 인프라, 머신러닝 적용시 문제 해결 방법 등 전문가의 최신 개발방법론과 노하우가 풍성합니다. 마소 391호의 주요 기사들을 IT조선 독자에게도 소개합니다.
[편집자주]
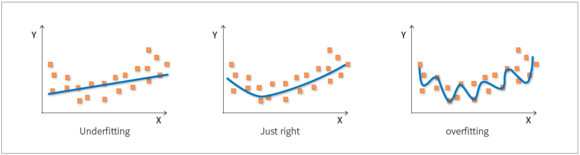
머신러닝에서는 언더피팅(Underfitting)과 오버피팅(Overfitting) 문제가 발생할 수 있다. 언더피팅은 데이터가 편향돼 예측에 실패하는 현상을 말하고, 오버피팅은 적은 데이터에서 많은 특징을 찾으려는 과정에서 정확도가 떨어지는 현상을 말한다.
허민석 SRA(Samsung Research America) 딥러닝 자연어처리팀 엔지니어는 머신러닝의 주요 문제인 언더피팅과 오버피팅의 발생원인 및 해결 방안에 대해 다뤘다.
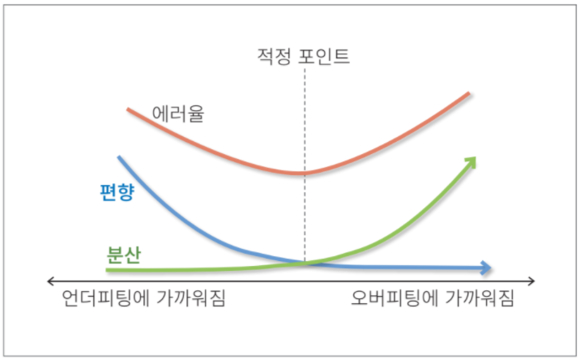
오버피팅은 데이터가 부족할 때 발생한다. 적은 데이터로 많은 특성에 부합하는 함수를 생성하기 때문에 분산이 커져 정확도가 떨어진다. 오버피팅은 보유 데이터를 7:3으로 나눠 7을 학습에, 3을 검증에 사용하는 검증 단계(Validation)를 거쳐 각각 정규화(Regularization) 또는 조기 종료(Early Stopping)로 극복할 수 있다.