
소프트웨어 전문지 마이크로소프트웨어 395호는 데이터 과학을 주제로 담았습니다. 데이터 과학에 대한 개론, 역사, 학습 방법, 실무 적용 사례 등 마소 395호 주요 기사들을 IT조선 독자에게도 소개합니다. [편집자주]
현재 스몰데이터(Small Data)라고 부르는 것도 타임머신을 타고 과거로 거슬러 올라가면 빅데이터가 된다. 데이터가 적든 많든 양과 관계없이, 과거 학계에서는 주로 통계 지식 바탕으로 데이터를 가져와 깔끔하게 만든 후에 분석해 모형을 만들었다. 현재는 데이터 사이언스(Data Science)를 통해 탐색적 데이터 분석 작업을 수행한 후 모형을 개발한다. 그 후 시각화 산출물을 만들어 알고리즘을 통해 데이터 제품과 서비스를 제작하는 과정을 거친다. 데이터 크기가 커진 것뿐 아니라 앞뒤로 추가적인 과정과 범위가 확대됐다.
빅데이터(Big Data) 저장과 관리는 기술적으로 난이도가 높은 작업이다. 일반적으로 대용량 데이터는 저장하고 관리하기 위해 지출하는 비용이 막대하기 때문에, 비용을 지출하는 비용센터(Cost Center)로 접근했다. 하지만 점점 다양한 데이터 분석방법이 제시되고, 미래를 예측하는 모형과 자동화를 통한 제품 및 서비스가 개발돼 수익을 창출시키는 수익센터(Profit Center)로 바꾼 성공사례가 늘고 있다.
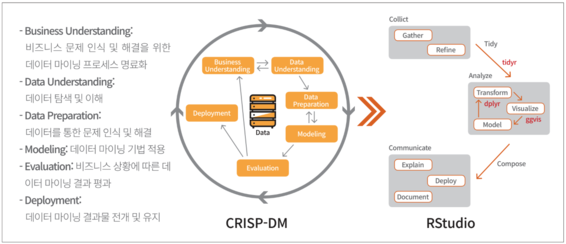
‘CRISP-DM(Cross-industry standard process for data mining)’은 데이터에서 유용한 무언가를 쉽고 빠르고 정확하게 찾을 수 있도록 모범사례(Best Practice) 형태로 모아 정리한 널리 알려진 데이터 마이닝 작업 흐름 모형 중 하나다. 현재 인기를 얻고 있는 기계학습(Machine Learning)이나 인공지능(AI) 제품과 서비스 개발 과정 작업 흐름을 비교해봐도 큰 차이점은 없어 보인다.
데이터 마이닝에 특화된 ‘CRISP-DM’을 타이디버스(Tidyverse) 작업 흐름과 비교해 보면, 큰 차이점은 데이터 사이언스 속 본질적인 가치에 집중하고 있다는 점을 들 수 있다. 아마도 ‘CRISP-DM’ 시절 이후 개발된 많은 부분이 자동화되거나 데이터 공학(Data engineering), 웹 공학(Web engineering), 나아가 클라우드 IaaS/PasS 영역으로 흡수돼 데이터 과학자가 신경 쓸 필요가 없어진 것이 가장 큰 이유일 것이다.
최근 인기를 얻고 있는 기계학습(Machine Learning)이나 인공지능(AI)과는 별개로 몇 년 전부터 R스튜디오의 해들리 위컴(Hadley Wickham) 박사는 타이디버스를 통해 데이터 사이언스를 새롭게 정의하는 시도를 해 많은 호응을 얻고 있다. R 언어 기반 패키지는 1만 개가 넘게 활용된다는 점은 긍정적이지만, 각자 설계 원칙에 맞춰 제각기 개발된 부분이 많다. 그래서 손을 바꿔 다른 사람이 이어받아 유지 보수하면 초기에 세워진 설계 원칙과 철학이 많이 무너지기도 한다.
타이디버스는 그동안 R 패키지를 개발하면서 축적된 경험과 노하우를 기반으로 R 설계 원칙을 재정립했다. 수많은 기여자의 도움을 받아 데이터 사이언스를 체계적으로 집대성했다는 평가를 받고 있다. 특히, 데이터 과학자 및 데이터 실무자에게 큰 도움을 줬고, 데이터 사이언스 오픈소스 운동의 커다란 동력으로 받아들여지고 있다.
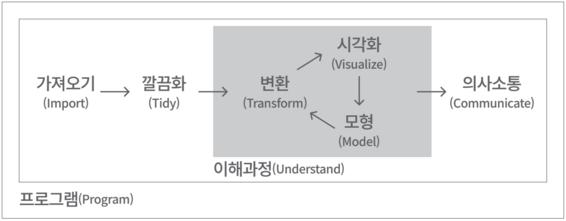
엉망진창인 R 도구상자(Messyverse)와 비교를 하기도 하지만, 타이디버스는 패키지라는 관점보다 유닉스(Unix) 철학처럼 데이터 사이언스에서 하나의 철학적 지침으로 접근하는 것이 일반적이다.
이광춘 필자의 ‘데이터 사이언스, 타이디버스로 향하다’에 대한 자세한 내용은 ‘마이크로소프트웨어 395호(https://www.imaso.co.kr/archives/4654)’에서 확인할 수 있다.