
소프트웨어 전문지 마이크로소프트웨어 395호는 데이터과학을 주제로 담았습니다. 데이터과학에 대한 개론, 학습 방법, 실무 적용 사례, 학계 등 마소 395호 주요 기사들을 IT조선 독자에게도 소개합니다. [편집자주]
쏘카는 데이터 기업이다. ‘기술과 데이터로 모빌리티를 혁신하자'라는 비전을 가지고 있고, 대표부터 경영진, 모든 팀원까지 데이터에 대한 관심이 많고 적극적이다. 사실 많은 기업에서 대표나 경영진, 구성원이 데이터를 이해하지 못해서 데이터 활용을 하지 못하는 것을 생각하면, 쏘카는 좋은 데이터 기업이 되기 위한 조건을 이미 많이 갖춘 셈이다. 하지만 쏘카에는 2가지 중요한 문제가 있었다. 좋은 데이터 팀이 없었고, 좋은 데이터 기술이 없었다.

쏘카에 데이터 팀이 아예 없던 것은 아니었지만, 전반적으로 팀 운영이 잘 안 됐다. 팀이 만들어진 지 1년, 팀원 근속이 평균 6개월 정도 된 신생팀이었다. 여러 이유로 기존 팀장이 퇴사한 상태였고, 팀원 몇 명은 퇴사를 앞두고 있었다. 남은 팀원은 리더십과 방향성이 부족한 상태로 하루하루 여러 팀의 데이터 분석 요청이나, 대시보드 등 업무를 하는 상태였다.
간절하게 변화가 필요한 시점이었다. 우선 데이터 인프라를 개편해야 했고, 좋은 팀원도 더 필요했다. 무엇보다 팀에서 하는 일을 다시 정립해야 했다. 일들은 마치 엉킨 실타래처럼 연결돼 있었다. 좋은 팀원이 없다면, 데이터 인프라도 새로 구축할 수 없고 팀에서 하는 일도 현재하는 일만 겨우 할 수 있을 것이다. 마찬가지로 인프라가 엉망인 곳에 좋은 사람들이 오고 싶어 하지 않을 것이고, 일도 제대로 할 수 없을 것이다.
데이터 인프라를 새로 구성하는 일은 얽힌 일 중 가장 먼저 할 수 있는 일이었지만, 인프라를 개선하는 일을 처음부터 하지는 않았다. 가능하면 빠르게 움직이고 싶었고, 기존 인프라가 나쁘지 않다면 당분간은 사용할 수 있다고 생각했기 때문이다.
기존에 사용하던 인프라는 오라클 데이터베이스에 데이터 웨어하우스를 구축하고, 서비스에 사용하는 MySQL 데이터베이스를 복제(Replication) 및 CDC(Change Data Capture) 솔루션을 이용해 중요한 테이블에 대한 변화분을 기록하는 식으로 시스템이 구성돼 있었다. ETL(Extract, Transform, Load)을 위한 솔루션도 준비돼 있었고, 수십 개 ETL 작업이 데이터 마트를 만들고 있었다. 이 정도면 당장 필요한 일은 할 수 있고 전혀 나쁘지 않다고 생각했지만, 의외로 새로 조인한 구성원보 기존 팀원이 새로운 데이터 인프라를 만들고 싶어 했다.
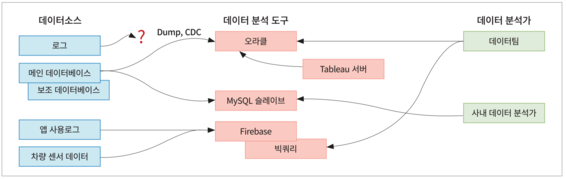
또한 계약상 오라클은 2018년까지는 무료로 이용할 수 있지만, 2019년부터는 상당히 큰 비용을 내야 하는 상황이었다. 거기에 오라클 데이터베이스를 많이 사용하지 않고 있음에도 용량이 이미 많이 차 있었고, 속도도 만족스럽지 못했다. 이럴 바에는 오라클을 그대로 사용하는 것보다는 새롭게 인프라를 구성해야겠다고 생각했다.
새 인프라에 대한 특별한 요구사항이 있는 것은 아니었지만, 기존에 사용하던 오라클 기반의 데이터 웨어하우스보다 여러 방면에서 개선될 것을 기대하며 계획했다.
첫 번째로는 빅데이터 기술을 활용하고자 했다. 기존 인프라에 처리할 수 있는 데이터 볼륨이나 속도 면에서 큰 불만이 있는 것은 아니었지만, 점점 관계형 데이터베이스로 처리할만한 한계에 가까워지고 있었다. 새로운 인프라에서는 빅데이터 기술을 통해 전반적인 속도향상을 도모하고, 데이터가 매우 커지는 차량 궤적 같은 데이터를 더 원활하게 활용하고자 했다.
다음으로는 높은 생산성을 낼 수 있는 인프라를 만들면 좋겠다고 생각했다. 쏘카 기존 데이터 인프라도 그랬듯이 고전적으로는 ETL 작업을 통해 여러 용도에 맞게 데이터를 준비하고 분석 등을 한다. 이런 방법은 잘 작동하는 방법이지만, 중간 데이터를 관리하는데 점점 많은 관리 비용이 들고 어떤 작업을 하는데 많은 단계를 추가함으로써 민첩성과 생산성을 떨어트리는 방법이기도 하다. VCNC에서 비트윈 데이터를 다룰 때는 클라우드를 활용해 강력한 컴퓨팅 파워를 통해 데이터를 미리 준비하는 작업을 생략하고 로우 데이터(Raw data)에서부터 최종 결과물까지 직접 가공함으로써 관리 비용을 줄이고 데이터 분석가의 생산성을 높였다. 덕분에 적은 인원으로 많은 일을 처리했던 경험이 있었기 때문에 이런 방법을 비슷하게 활용해보고 싶었다.
또한, 구성하기가 매우 쉽고, 간편하게 사용할 수 있어야 했다. VCNC에서는 엔지니어링팀이 4명이었고 모두가 숙련된 팀이었기에 원하는 만큼 엔지니어링에 투자할 수 있었다. 하지만 쏘카와 팀을 합쳐놓으니 각자의 역할이 바뀌게 되었고 엔지니어링에 시간을 투자할 수 있는 팀원이 단 한 명밖에 남지 않았다. 따라서 제한된 인력으로 최소 시간을 투자해 얻을 수 있는 인프라를 원했다. 새로운 인프라를 학습해 사용하는 것도 마찬가지로 빨리 됐으면 하는 생각이었다.
여러 고민 끝에 구글 빅쿼리(Google BigQuery)를 활용하기로 했다. 이렇게 결정한 가장 큰 이유는 사내에 데이터그룹 외 각 부서에 SQL을 사용할 줄 아는 데이터 분석가가 많고, 분석가가 익숙한 도구로 계속해서 일을 잘할 수 있게 하는 것이 좋겠다고 생각했기 때문이다. 또한 이미 앱 사용 로그나 차량 센서데이터를 구글 파이어베이스(Firebase)를 통해 빅쿼리에서 볼 수 있는 것과 사용한 만큼 종량제로 요금이 부과되는 관리형 서비스기 때문에 무척 빠르고 쉽게 적용할 수 있다는 점도 결정에 큰 영향을 미쳤다.
김상우 필자의 ‘핵심 비즈니스를 혁신하는 데이터팀 이야기’에 대한 자세한 내용은 ‘마이크로소프트웨어 395호(https://www.imaso.co.kr/archives/4654)’에서 확인할 수 있다.