
‘AI의 대중화’ 시대다. [누구나 개발자] 1편에서는 국내 유일의 소프트웨어전문지인 마이크로소프트웨어(이하 마소) 400호에 인공지능에 대한 이야기를 풀어낸 ‘스팟라이트’ 섹션의 기고를 소개한다. [편집자주]
① AI is everywhere
② 오픈소스 AI 개발 도구가 애저 클라우드와 만났을 때
③ 애저에서 머신러닝을 한다는 것...머신러닝이 클라우드, 오토 ML과 ML옵스를 만났을 때
④ 인텔리전트 ‘엣지와 클라우드’의 궁극적 지향점
⑤ 오피스 안으로 들어온 AI
⑥ 누구나 AI 전문가로!
⑦ 양자 컴퓨팅 활용의 지름길 ‘애저 퀀텀'
⑧ 알고리즘랩스 "인공지능 기술 보편화에 기여하겠다"
#오픈소스 AI 개발 도구가 애저 클라우드와 만났을 때

알파고가 이세돌과 격돌한 게 어느덧 4년이다. 이제는 인공지능 비서라 불리는 AI 스피커뿐만 아니라 스마트폰에 탑재된 AI 음성인식 서비스, AI가 추천하는 광고 및 서비스는 물론이고, 자동차 및 로봇을 비롯해 헬스케어, 심지어는 예술, 법조계까지 전방위로 AI가 도전장을 내밀고 있다. 그렇다면 AI를 구현하는 기술 및 개발 도구는 그동안 어떤 변화가 있었을까? AI를 구현할 수 있던 과거의 오픈소스 시절부터, 클라우드 발전으로 이에 장점을 더한 다양한 오픈소스 개발 툴의 현재를 살펴보기로 하자.
[대제] 머신러닝 구현과 함께해 온 다양한 오픈소스 개발 툴
오늘날과 같이 AI가 발전할 수 있었던 대표적인 요인을 꼽자면 바로 딥러닝 기술이 컴퓨팅 파워와 함께 발전한 덕택일 것이다. 이러한 발전에 영향을 미친 또 다른 요인으로 다양한 오픈소스 딥러닝 개발 프레임워크 생태계를 언급하고자 한다.
파이토치(PyTorch), 텐서플로(TensorFlow), 케라스(Keras) 등 여러 오픈소스 프레임워크가 있다. 많은 AI 모델러뿐만 아니라 실무에서도 그리고 AI를 배우고자 하는 입문자들도 해당 오픈소스 프레임워크를 적어도 한 번은 사용해 보는 것 같다. 이와 같은 AI 개발 툴에 대한 오픈소스 생태계는 2010년 11월, 테아노(Theano)라는 오픈소스 머신러닝 프레임워크를 통해 본격적으로 발전했다. 사실 그 전, 2000년대에도 딥러닝은 아니지만 머신러닝 구현과 함께해 온 오픈소스 개발 툴이 여럿 있었다. 그중 기억에 남는 오픈소스가 있다면, 바로 웨카(Weka)와 libsvm이다.
웨카는 뉴질랜드 와이카토 대학에서 개발한 GNU 라이선스 기반 오픈소스다. 데이터 분석 및 예측을 위해 여러 머신러닝 알고리즘을 실행하고 시각화하는 도구를 포함한다. 자바로 구현됐으며, GUI(Graphical User Interface)를 통해 동일한 데이터 집합에 대해 여러 머신러닝 알고리즘을 실행하고 비교해볼 수 있다. 딥러닝이 발전하기 전까지 다양한 종류의 데이터를 기반으로 지도 학습(Supervised Learning) 및 비지도 학습(Unsupervised Learning) 알고리즘을 누구나 실행해 보고 정확도를 확인·비교할 수 있었다. 머신러닝에 대한 이론을 데이터로 확인하기 매우 유용한 오픈소스였다.
libsvm은 딥러닝 이전 뛰어난 성능으로 많은 주목을 받았던 서포트 벡터 머신(Support Vector Machine) 알고리즘을 구현한 라이브러리다. 특히 당시 넷플릭스와 같은 추천 시스템을 구현할 때, 해당 알고리즘을 활용해 구현하는 경우가 많았을 정도로 인기가 있었다.
#딥러닝의 발전으로 도래한 AI 오픈소스 개발 툴 춘추전국시대
딥러닝이란 용어가 본격적으로 사용된 것은 2006년 토론토 대학의 제프리 힌튼(Geoffrey Hinton) 교수가 심층 신뢰 신경망(Deep Belief Network)이라는 효과적인 딥러닝 알고리즘을 논문으로 발표하면서부터이다. 이후 학계에서 점점 많은 데이터와 컴퓨팅 파워를 활용해 모델의 정확도를 계산해 보고 보다 나은 정확도를 보장하는 딥러닝 모델이 무엇인지 비교하기 시작한다. 또한 중앙처리장치(CPU)가 맡았던 응용 프로그램 계산을 그래픽 카드 프로세서인 GPU에서 처리할 수 있는 기술이 발전함에 따라, 이론상의 딥러닝 모델이 일정 성능을 보장하는 구현 가능한 딥러닝 모델로의 실현이 가능해졌다. 이전에는 그래픽카드가 컴퓨터 화면 출력 계산을 위해서만 사용됐다.
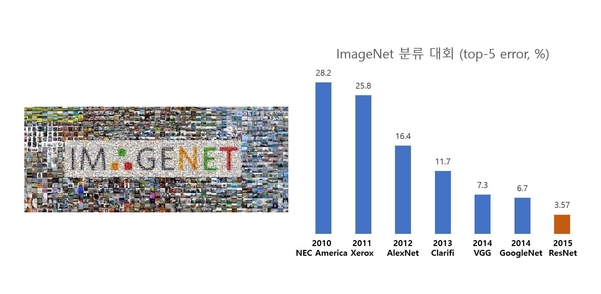
2012년 글로벌 이미지 인식 경진대회인 ILSVRC(ImageNet Large Scale Recognition Challenge)에서 딥러닝을 기반으로 한 모델이 83.6%로, 무려 10% 이상 획기적으로 정확도를 개선한 사건이 발생한다. 제프리 힌튼 교수의 제자인 알렉스 크리제브스키(Alex Krizhevsky) 팀이 알렉스넷(AlexNet)이라는 딥러닝 모델을 구현한 것이다. GPU 연산을 활용해 학습 시간을 단축했을 뿐만 아니라 소스 코드를 공개해, 해당 딥러닝 모델을 직접 구현하는 AI 연구 및 개발자가 점차 증가했다. ILSVRC에서 2011년까지 정확도는 0.1~2% 정도만 향상됐었다.
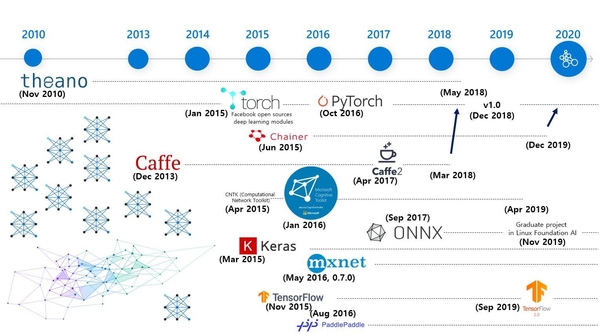
이후 2015년부터는 마치 춘추전국시대를 연상할 정도로 정말 다양한 머신러닝, 딥러닝 오픈소스 프레임워크 개발 툴이 역동적 변화를 거듭하기 시작했다. 먼저 토치(Torch)라는 루아(Lua) 스크립트 언어를 기반으로 하는 프레임워크가 있었다. 페이스북은 2015년 1월, 토치를 기반으로 하는 딥러닝 모듈을 오픈소스로 공개했다. 이후 파이썬을 위한 오픈소스 머신러닝 라이브러리인 파이토치 오픈소스를 2016년 10월 내놨고, 2018년 12월 1.0 버전을 정식 출시했다. 뿐만 아니라 구글에서는 2015년 11월 텐서플로라는 딥러닝 프레임워크를 오픈소스로 공개하고 지속적으로 버전업을 하고 있다. 중국 바이두에서는 패들패들(PaddlePaddle)이라는 딥러닝 프레임워크를 2016년 8월 공개했다.
한 가지 주목할 만한 점은 적극적이고 활발한 오픈소스 생태계에서 모든 오픈소스가 살아남지는 못했다는 것이다. 2010년 11월 출발했던 테아노는 2018년 5월, 더 이상 적극적으로 개발하지 않겠다고 선언했다. 2015년 6월 일본계 회사 프리퍼드 네트워크(Preferred Network)에서 개발을 주도했던 체이너(Chainer)라는 오픈소스는 2019년 12월, 향후 개발을 파이토치로 전환할 것이라고 선언했다. 카페는 미국 UC 버클리에서 연구하던 양칭 지아(Yangqing Jia)가 페이스북에 입사하면서 2017년 4월, 카페2를 릴리즈했는데, 2018년 3월, 카페2 기능을 페이스북에서 적극적으로 주도하던 파이토치에 통합하기도 했다. 이와 같은 딥러닝 개발 프레임워크에 대해 오픈소스 진영에 여러 변화가 생기는 한편, 인공신경망을 파이썬으로 쉽게 만들 수 있도록 여러 오픈소스에 대한 계산 엔진을 선택해 사용 가능한 케라스 오픈소스가 발전했다. 아마존은 아파치(Apache) 재단 프로젝트인 엠엑스넷(MXNet) 오픈소스 개발을 지원했다. 이렇듯 개발자 입장에서 다양한 선택지가 생긴 것은 환영할 만한 일이라 할 수 있겠다.
#현실에서의 오픈소스 AI 툴의 어려움 그리고 상호 운용성
이처럼 AI 기술이 발전하게 된 또 다른 배경에는 오픈소스가 주는 긍정적이면서 선한 영향력이 있었다. 그런데 여전히 많은 기업에서 AI를 적용하는 데 어려움을 겪고 있는 것 또한 사실이다. AI 적용을 위한 데이터 수집에서부터 숙련된 AI 모델러 및 개발자가 부족한 현실적인 이유도 있겠지만, 오픈소스와 관련해서 겪는 어려운 점으로는 ‘오픈소스는 상용 서비스에 적용하기 어렵다’는 인식이 있을 수 있다. 오픈소스는 완성도가 부족해 상용 서비스에 적합하지 않다는 이야기를 듣곤 한다. 하지만 AI 영역에서 설명했던 여러 오픈소스 프레임워크는 교수나 연구자뿐만 아니라 현업에서도 사용되는 프레임워크이기 때문에 완성도 면에서는 상용 소프트웨어에 절대 뒤지지 않는다. 뿐만 아니라 마이크로소프트 애저 같은 클라우드 기업도 이러한 주요 오픈소스 프레임워크를 기본으로 지원하고 있을 정도다. 오픈소스 프레임워크를 사용하는 것 또한 좋은 선택지가 될 것이다.
#상호 운용성을 해결하는 오픈소스를 위한 데이터 포맷, ONNX
2017년 9월, 마이크로소프트와 페이스북이 공동으로 개발한 오픈 뉴럴 네트워크 익스체인지(Open Neural Network Exchange. 이하 ONNX)에 대한 발표가 있었다. AI 개발자들이 이미 사용 중인 프레임워크를 딥러닝 학습 모델의 필요에 따라 쉽게 다른 것으로 바꿀 수 있게 하는 프레임워크로, AI 프레임워크에 대한 상호 변환과 여러 배포 대상을 공통의 모델로 하는 데이터 포맷에 해당한다.

#고성능 오픈소스 ‘ONNX 런타임’으로 가속화하는 오픈모델 기반 AI 구현
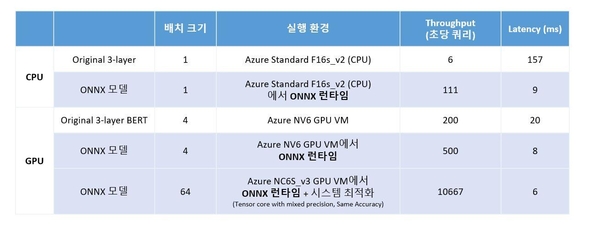
ONNX 데이터 포맷으로 서로 다른 오픈소스 프레임워크를 사용하더라도 동일한 모델 형식으로 저장하는 것은 가능해졌으나, 해당 데이터 포맷을 어떻게 배포해 최적의 성능을 보장하는지에 대한 문제를 해결한 것은 아니다. 2018년 12월, 마이크로소프트에서는 ONNX 데이터 포맷으로 저장된 모델을 리눅스, 윈도, 맥OS에서 고성능으로 실행 가능한 ‘ONNX 런타임’을 깃허브(github.com/microsoft/onnxruntime)에 공개했다.
이에 따르면 MIT 라이선스로 관심 있는 누구나 소스 다운로드와 설치뿐만 아니라 컨트리뷰션도 가능하다. 확장 가능하고 모듈화한 프레임워크로 설계해 파이썬, C++, C#, C, 자바 같은 다양한 프로그래밍 언어를 지원한다. GPU 가속을 위한 쿠다(CUDA) 라이브러리와 인텔 하드웨어를 위한 시각 추론, 신경망 최적화를 위한 툴킷인 오픈비노(OpenVINO) 등 다양한 하드웨어 가속 옵션에서 ONNX 런타임으로 실행할 수 있다.

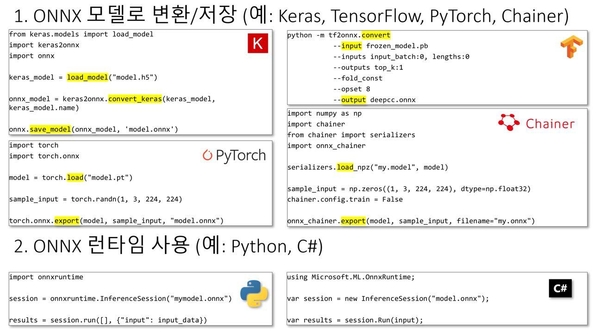
ONNX와 ONNX 런타임을 함께 사용하면 어떤 오픈소스 AI 개발 툴을 사용하더라도 ONNX 모델로 변환해 저장한 다음, ONNX 런타임을 통해 실행할 수 있다. 아래 그림은 ONNX 모델로 변환 후 저장한 다음 ONNX 런타임을 사용하는 샘플 코드이다.
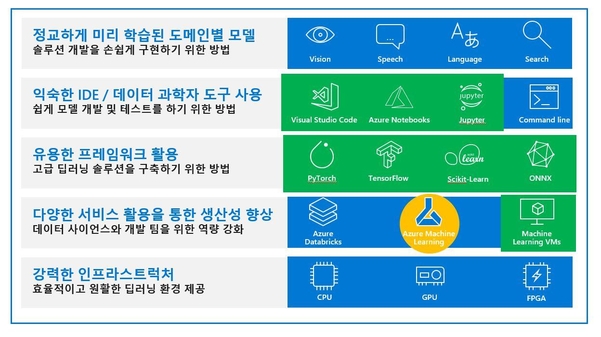
주피터 노트북은 웹 브라우저에서 파이썬 코드를 단계적으로 실행해 볼 수 있는 오픈소스 웹 애플리케이션으로, 텍스트 및 실행 코드, 실행 결과, 관련 그래픽 및 시각화를 캔버스 단위로 저장해 공유할 수 있다. PC나 노트북에 직접 설치해 사용할 수도 있지만, 이 경우 캔버스 파일을 전달해야 공유되므로 실시간 공유가 어렵다는 단점이 있다. 애저 머신러닝 서비스에서는 노트북 파일을 작성하고 컴퓨팅 머신을 생성해 클라우드에서 노트북 결과를 확인할 수 있다. 별도의 애저 노트북 서비스(notebooks.azure.com)도 있는데 4기가바이트(GB) 메모리와 1GB 데이터 제한이 있지만 무료로 사용 가능하다.
2. 비주얼 스튜디오 코드
무료로 사용 가능한 IDE임에도 불구하고 확장팩을 설치하면 애저 서비스와의 연동이 쉽다. 애저 확장팩은 비주얼 스튜디오 코드를 실행한 후, 왼쪽에서 확장에 아이콘을 클릭한 다음 ‘애저’로 검색하면 주요 애저 서비스별로 확장팩을 확인할 수 있다. ‘애저 머신러닝 서비스’의 확장팩은 aka.ms/vscode-plugin-azureml을 통해 다운로드할 수 있다. 애저를 사용하지 않더라도 파이썬 확장팩(aka.ms/vscode-python)을 설치하면 주피터 노트북 파일인 .ipynb 확장자를 가진 파일을 IDE에서 직접 열어서 확인하는 기능을 제공한다. 다른 사람이 만든 주피터 노트북 파일을 확인하고자 할 때, 번거롭게 주피터 노트북 개발 환경을 구성할 필요 없이 간단히 열어서 확인할 수 있다. 필요한 경우에는 주피터 노트북을 비주얼 스튜디오 코드가 실행되는 로컬 환경에서 설치해 한 줄씩 실행하는 것 또한 가능해진다.
3. 컨테이너 환경에 대한 지원
애저 머신러닝 서비스에서는 사용자가 직접 오픈소스를 활용해 만든 모델 파일과 ONNX 데이터 포맷으로 저장된 모델을 업로드할 수 있다. 이때 등록된 모델은 하나 이상의 파일에 대한 논리적인 컨테이너인데 실제적으로는 도커에서 사용하는 컨테이너 단위와 같다. 따라서 해당 컨테이너를 쿠버네티스와 같은 컨테이너 오케스트레이터를 통한 관리가 가능할 뿐만 아니라 데브옵스와 연계도 쉽다는 장점이 있다.
4. 데이터 과학자를 위한 가상 머신
1-3을 보다 잘 활용하기 위해 별도의 개발 환경을 갖춰야 한다면, ‘애저 데이터 사이언스 버추얼 머신’을 사용하는 것도 고려해보자. 머신러닝·딥러닝을 위한 오픈소스 AI 개발 툴이 내장된 전용 가상 머신을 애저 클라우드에서 사용할 수 있다. 즉, 추가적인 머신러닝, 딥러닝 툴 설치 없이 바로 가상 머신에 접속해 개발 및 애저 머신러닝 서비스 환경에서 개발할 수 있다. 윈도, 윈도 서버, 우분투 리눅스 세 가지 버전으로 제공하며, 운영체제 호환성에 따라 지원되는 개발 툴 목록에 차이가 있을 수 있으니, aka.ms/dsvm-tools 링크를 참고하자.
#진정한 오픈소스를 기반으로 한 ‘오픈’ AI 협력 및 개발을 위해
AI, 특히 딥러닝과 관련한 여러 알고리즘과 모델이 발전했던 시기를 돌아보면서, 마이크로소프트의 AI 분야 오픈소스 활동과 클라우드를 기반으로 하는 여러 오픈소스들이 어떻게 활용돼 AI 클라우드 서비스로 발전했는지를 살펴봤다. 참고로 클라우드 기반으로 제공되는 모든 서비스가 오픈소스를 바탕으로 제공되는 것은 아니다. 예를 들어, 애저에서 제공하는 컴퓨터 비전, 텍스트 분석 서비스 등은 마이크로소프트에서 방대한 양의 데이터 및 학습을 통해 API 키 액세스로 모델을 사용할 수 있는 형태로 제공한다. <표1>은 curl 명령어를 사용해 이미지에 대한 컴퓨터 비전 분석 결과를 API 호출로 얻은 것이다.

#마이크로소프트웨어 #마소 #개발자 #인공지능 #사티아나델라 #마이크로소프트 #MS #윈도문의는마이크로소프트에 #마이크로소프트웨어와마이크로소프트는다릅니다 #누구나개발자