
코드명 ‘폰테 베키오(Ponte Vecchio)’로 알려진 인텔의 데이터센터 GPU가 공개됐다.
인텔은 오는 13일 미국에서 열리는 슈퍼컴퓨팅 2022(SC22) 컨퍼런스를 앞두고 고성능 컴퓨팅(HPC)과 인공지능(AI) 시장에 최적화된 새로운 GPU 제품군 ‘인텔 데이터센터 GPU Max 시리즈’를 발표했다.
8일 온라인으로 진행한 사전 브리핑에서 인텔은 ‘인텔 데이터센터 GPU Max 시리즈’가 최대 2스택 구성에서 128개의 Xe-HPC 코어로 주요 벤치마크와 애플리케이션에서 엔비디아의 A100 GPU 대비 크게는 두 배 이상의 성능을 제공한다고 밝혔다.
‘인텔 데이터센터 GPU Max 시리즈’는 최대 128개의 Xe HPC 코어와 최대 128기가바이트(GB)의 HBM2e 메모리의 조합으로 FP64 기준 52테라플롭스(TFlops/s)의 연산 성능을 제공한다. 제품군은 PCIe 카드 형태와 OAM 모듈, 4개 OAM 모듈이 결합된 서브시스템 형태로 공급되며, 주요 파트너들을 통해 15개 이상의 시스템 디자인이 선보일 계획이다.

이 GPU는 최대 두 개 스택 구성에서 128개의 Xe 코어, 128개의 레이트레이싱 유닛, 8개의 하드웨어 컨텍스트, 8개의 HBM2e 컨트롤러, GPU간 직접 연결을 위한 16개의 Xe 링크 등을 갖추고 있다.
인텔은 ‘인텔 데이터센터 GPU Max 시리즈’에도 메모리 대역폭과 용량 모두를 극대화하기 위한 선택으로, 최대 64메가바이트(MB)의 L1 캐시, 최대 408MB에 이르는 람보(Random Access Memory, Bandwidth Optimized) L2 캐시와 함께, 최대 128GB의 HBM2e 메모리를 사용했다.
이 중 408MB의 L2 캐시는 두 개 스택에 나뉘어 있으며, 각 스택에서는 베이스 타일에 144MB, 람보 타일에 60MB가 구성되어 있고, 최대 읽기 대역폭은 13TB/s 정도 성능이다. 128GB HBM2e의 대역폭은 3.2TB/s 이며, 레지스터 레벨에서부터 L1, L2, HBM으로 내려오는 메모리 계층 구조에서 대용량 L2 캐시를 사용해 데이터의 메모리 계층 이동을 줄이고 캐시 적중률에 따른 성능적 장점을 극대화했다.
애플리케이션 지원 측면에서는, 이미 30여 개 이상의 애플리케이션과 주요 프레임워크, 벤치마크 등이 인텔 데이터센터 GPU Max 시리즈를 지원하고 있다. 원API(one API) 플랫폼을 활용해 CPU, GPU, 다양한 가속기 등 하드웨어의 역량 활용을 극대화할 수 있다.
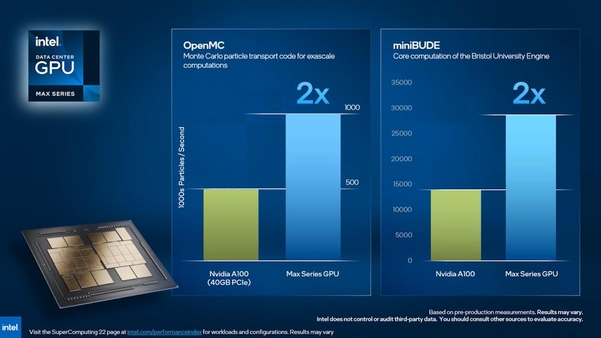
인텔은 이 ‘데이터센터 GPU Max 시리즈’가 엔비디아(NVIDIA)의 A100 40GB PCIe 모델 대비 OpenMC나 miniBUDE에서는 두 배, 금융 분석 애플리케이션 Riskfuel에서는 2.4배, 가상 리액터 시뮬레이션 ExaSMR에서는 1.5배 높은 성능을 제공한다고 소개했다.
한편, 인텔은 데이터센터 GPU Max 시리즈 제품들이 전통적인 GPU 프로그래밍 모델인 SPMD/SIMT, 전통적인 CPU 프로그래밍 모델인 SIMD를 모두 지원 가능한 유연성을 제공한다는 점도 덧붙였다.


이 중 PCIe 카드 모델인 ‘인텔 데이터센터 GPU Max 1100’은 1스택 Xe-HPC 구성에서 56개 Xe 코어와 48GB HBM2e 메모리를 갖췄으며, Xe 링크를 통해 최대 4개 카드까지 카드간 직접 연결이 가능하고, TDP는 300W다. OAM 모듈 형태로 나오는 인텔 데이터센터 GPU Max 시리즈 1350, 1500 GPU는 온전한 2스택 Xe-HPC 구성을 기반으로 하며, 각각 112, 128 Xe 코어와 96GB, 128GB HBM2e 메모리를 갖췄다. 두 모델 모두 최대 8개 OAM간 연결 가능한 Xe 링크 기능을 갖췄으며, TDP는 각각 450, 600W로 소개됐다.
4개 OAM이 결합되는 ‘서브시스템’의 경우, 성능 사양은 인텔 데이터센터 GPU Max 시리즈 1350, 1500 GPU 대비 정확히 네 배로, 메모리는 최대 512GB, 메모리 대역폭은 최대 12.8TB/s에 이른다. TDP 또한 네 배로, 1500 GPU의 네 개 구성시 TDP는 2400W가 된다.
인텔은 ‘인텔 데이터센터 GPU Max 시리즈’ 제품군을 사용한 시스템 디자인이 주요 파트너들을 통해 15개 이상의 디자인으로 제공될 것이라고 전했다. 대표적인 사례로는 미국 아르곤국립연구소의 오로라(Aurora) 슈퍼컴퓨터를 들 수 있다.
한편, 인텔은 이번 발표에서 HPC 시장을 위한 제품 포트폴리오에 대해, 다음 세대의 인텔 데이터센터 GPU는 코드명 ‘리알토 브릿지(Rialto Bridge)’가 될 것이라고 소개했다.
리알토 브릿지는 최대 160개의 개선된 Xe HPC 코어를 탑재하고, OAM당 최대 800W의 TDP로 수냉 방식이 기본으로 고려된다. 현재의 ‘폰테 베키오’와 향후의 ‘리알토 브릿지’는 기본적으로 같은 서브시스템을 기반으로 해, 현재의 시스템에서 차세대 ‘리알토 브릿지’로의 업그레이드 가능한 호환성이 제공된다.
향후 제온 스케일러블 프로세서 이외의 CPU, GPU, 가속기 포트폴리오는 하나의 패키지에 CPU, GPU, 고대역폭 메모리 등이 모두 통합 XPU ‘팔콘 쇼어(Falcon Shores)’에서 통합될 계획이다. 이 ‘팔콘 쇼어’에서는 용도에 따라 x86 CPU 코어와 Xe GPU 코어, 고대역폭 메모리 등을 유연하게 조합 구성 가능할 것으로 보인다. 이를 통해 컴퓨트 밀도나 메모리 용량, 대역폭 등에서 더욱 워크로드에 최적화된 HPC 구성을 구현할 수 있을 것으로 기대된다.
사전 브리핑에서 제프 멕베이(Jeff McVeigh) 인텔 슈퍼컴퓨팅 그룹 총괄 및 부사장은 "인텔 데이터센터 GPU Max 시리즈 제품군은 지금까지의 데이터센터용 GPU들에서 아쉬운 점이었던 메모리 용량과 성능, 소프트웨어 측면의 포팅과 리팩토링 문제에 대한 해결책을 제시하는 제품이다"며, "원API를 통해 CPU와 GPU간에 좀 더 수월하게 코드를 공유하고, 전 세계가 당면한 문제를 더 빨리 해결할 수 있게 지원할 것이다"고 덧붙였다.
권용만 기자 yongman.kwon@chosunbiz.com