

◆엔비디아 호적수 '인텔'
종합적인 제품군을 보유한 인텔이 가장 대표적인 예다. 인텔은 3억5000만달러(3천800억원)에 인수한 스타트업 '너바나 시스템즈(Nervana Systems)'의 기술을 바탕으로 딥러닝 전용 'NNNP(Nervana Neural Network Processor)' 칩을 개발했다. 코드명은 레이크 크레스트(Lake Crest)다.

인텔은 데이터센터 시장을 위해 이 칩을 개발했다. 슈퍼 에이트로 불리는 미국의 구글, 아마존, 페이스북, 마이크로소프트(MS)와 중국 바이두, 알리바바, 텐센트, 차이나모바일이 주 목표다.
NNNP 칩은 구글 TPU(Tensor Processing Unit)와 유사한 기능을 수행한다. 인텔은 이를 이유로 구글과 경쟁 관계에 있는 기업을 중심으로 협력을 추진하고 있다. 현재 페이스북에 대규모의 NNNP 칩을 설치하고 있다는 소문이 나온다.
인텔은 2015년에 167억달러(18조원)로 인수한 알테라(Altera) 기술도 보유했다. 인텔은 알테라를 인수하고 FPGA(Field Programmable Gate Array)를 이용해 인공지능 수요에 대응한다는 전략이다.

인텔은 마이크로소프트와 협력해 스트라틱스 10을 활용한 브레인웨이브(Brainwave) 사업을 추진하고 있다. 빙(Bing)과 스카이프(Skype)에 이를 적용하고 그 활용분야를 단계적으로 확대할 예정이다.
인텔은 인간의 뇌를 닮은 컴퓨터칩 '뉴로모픽(Neuromorphic)'을 활용하기 위한 노력도 진행 중이다. 뉴로모픽은 인간 신경세포를 실리콘에 구현한 형태의 새로운 컴퓨팅 패러다임이다. 뉴로모픽 칩의 코드명은 로이히(Loihi)다.
로이히 칩은 공식적으로 발표된 내용이 많지 않다. 하지만 업계는 뉴로모픽 칩의 장점인 우수한 에너지 효율성을 기대한다. 소문에 따르면 기존 칩과 비교해 1000배의 에너지 효율성을 내기 위한 도전이 진행된다.
인텔의 최종 목표는 서버가 아닌 종단장치(Edge Device)다. 인텔은 2017년 7월 시각처리 전용 인공지능 칩 모비디우스(Movidius)를 출시했다. 모비디우스는 마이리드 X 비전프로세싱 유닛(Myriad X Vision Processing Unit, VPU) 제품으로, 2016년 인수한 모비디우스 기술이 바탕이다.
이 칩은 자율주행 자동차, 고성능 드론, IoT 장비 등에 탑재되는 저전력 인공지능 칩이다. 딥러닝 성능은 1 테라플롭스 정도로 추정되며 인공신경망 및 이미지 처리에 특화됐다. 칩 외에도 USB 단자에 꽂을 수 있는 "컴퓨트 스틱(Compute Stick)"의 형태로도 판매된다.
◆베일 속 구글, TPU2로 왕좌 노려
다음으로 살펴볼 기업은 구글이다. 구글은 '알파고(AlphaGo)'에 사용했던 TPU의 후속인 TPU2를 텐서플로우 리서치 클라우드(Tensorflow Research Cloud)에 탑재해 서비스 중이다. 구글은 TPU를 독자 상품으로 판매하지 않고 구글 서비스에만 포함했다.
TPU2에 대해 알려진 것은 별로 없다. 하지만 공개된 내용을 바탕으로 추리하면 카드 형태로 메인보드에 장착된다. 딥러닝 성능은 180테라플롭스로 추정된다. GPU에 비해 15~30배의 성능과 30~80배의 전력효율성이 예상된다.
마이크로소프트는 인텔과 공동으로 추진하는 브레인웨이브 사업 외에 종단장치용 HPU(Holographic Processing Unit) 개발도 추진하고 있다. 이는 홀로렌즈(HoloLens) 헤드셋 등에 장착돼 시각과 청각 데이터 처리를 담당한다.
휴렛팩커드엔터프라이즈(HPE)는 딥러닝 및 고성능 컴퓨팅에 적합한 보조처리기 형태의 닷프로덕트 엔진(Dot-Product Engine) 칩을 개발하고 있다. 이 칩은 뉴로모픽 컴퓨터와 유사한 비노이만(non Von Neumann)형이며 자사의 멤리스터(Memrister)를 사용하는 것으로 알려져 있다.
일본 후지쯔는 최근 딥러닝 전용칩 DLU(Deep Learning Unit)를 발표했다. DLU는 경쟁제품과 비교해 10배의 전력 효율성을 목표로 한다. 이를 위해 후지쯔는 저정밀 계산을 해법으로 제시했다. 32·16·8비트 연산을 적절히 활용해 성능은 최대화 시키고 전력소모를 줄이겠다는 계산이다. DLU는 수 개 DPU(Deep Processing Unit)로 이뤄졌으며 하나의 DPU는 16개 DPE(Deep Processing Element)로 이뤄졌고 각 DPE는 8개 연산단위를 이룬다.
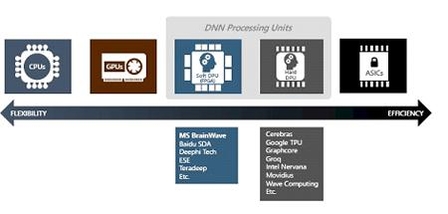
딥러닝처럼 동일한 형태의 계산이 반복되는 경우, 여러 형태의 계산을 두루 잘할 수 있는 CPU와 함께 특정한 계산만 잘하는 보조연산장치를 함께 쓰는 것이 효율적이다.
CPU 다음 유연한 형태는 GPU, 그 다음이 스타라틱스 등 FPGA를 이용한 소프트 딥러닝 칩, NNNP 등의 하드 딥러닝 칩, 그리고 ASIC(Application Specific Integrated Circuit)의 순서이다. 반대로 특정문제에 대한 성능은 반대로 ASIC이 가장 뛰어나며 CPU가 가장 떨어진다. 다양한 형태의 칩이 존재하는 이유는 해결해야 하는 문제 성격과 필요한 유연성에 따라 적합한 칩이 다르기 때문이다.
※ 외부필자의 원고는 IT조선의 편집방향과 일치하지 않을 수 있습니다.
이지수 소장은 미국 보스턴대학에서 물리학 박사를 했고 독일 국립슈퍼컴센터 연구원, 한국과학기술정보연구원(KISTI) 슈퍼컴퓨팅센터 센터장, 사단법인 한국계산과학공학회 부회장, 저널오브컴퓨테이셔널싸이언스(Journal of Computational Science) 편집위원, KISTI 국가슈퍼컴퓨팅연구소 소장을 거쳐 현재는 사우디 킹 압둘라 과학기술대학교(KAUST) 슈퍼컴센터장을 맡고 있습니다.
- [이지수 소장의 수퍼컴퓨터 이야기] AI 하드웨어 서밋으로 살펴본 AI 전용칩 최신 동향
- [이지수 소장의 수퍼컴퓨터 이야기] 코로나19 이후 고성능컴퓨팅 시장 전망
- [이지수 소장의 수퍼컴퓨터 이야기] 슈퍼컴 왕좌에 앉은 日 후가쿠…유효기간은 1년
- [이지수 소장의 수퍼컴퓨터 이야기] 온라인 인공지능 활용 서밋 참석기
- [이지수 소장의 수퍼컴퓨터 이야기] 슈퍼컴퓨터의 주요 부품은 누가 만들까
- [이지수 소장의 수퍼컴퓨터 이야기] 기업의 효율적인 AI 실천전략
- [이지수 소장의 수퍼컴퓨터 이야기] AI가 혁신 가져올 건강관리 분야는?
- [이지수 소장의 수퍼컴퓨터 이야기] 최초의 엑사급 슈퍼컴퓨터를 노린 ‘왕좌의 게임’
- [이지수 소장의 수퍼컴퓨터 이야기] 인간 뇌를 모방한 뉴로모픽 컴퓨터
- [이지수 소장의 수퍼컴퓨터 이야기] 양자컴퓨터 상용화 로드맵
- [이지수 소장의 수퍼컴퓨터 이야기]공급 대비 수요 줄인 美 트럼프 행정부 슈퍼컴 정책
- [이지수 소장의 수퍼컴퓨터 이야기] ISC18, 미국 슈퍼컴 왕좌 탈환하나
- [이지수 소장의 수퍼컴퓨터 이야기](56) 최첨단 슈퍼컴 시스템을 만드는 ‘CORAL’ 사업
- [이지수 소장의 수퍼컴퓨터 이야기] (55) 블록체인의 근본적인 변화가 필요한 이유
- [이지수 소장의 수퍼컴퓨터 이야기] (53) AI에 적합한 컴퓨터 칩…앞서나가는 엔비디아
- [이지수 소장의 슈퍼컴퓨터 이야기] (52)달아오르는 고성능 서버급 CPU 경쟁
- [이지수의 슈퍼컴퓨터 이야기(50)] 달아오르는 엑사급 슈퍼컴 개발 경쟁①...중국의 진격
- [이지수 소장의 슈퍼컴퓨터 이야기(51)] 달아오르는 엑사급 슈퍼컴 개발 경쟁②…미국과 일본의 추격
- [이지수 소장의 슈퍼컴퓨터 이야기(49)] 슈퍼컴퓨터 최대의 적은 '우주선(cosmic ray)'
- [이지수 소장의 슈퍼컴퓨터 이야기(48)] NASA는 어떻게 로켓을 개발할까
- [이지수 소장의 슈퍼컴퓨터 이야기(47)] 슈퍼컴, 수학 난제를 해결한다
- [이지수 소장의 슈퍼컴퓨터 이야기(46)] 데이터의 움직임에 주목하라②
- [이지수 소장의 수퍼컴퓨터 이야기] 슈퍼컴퓨터와 AI가 바꾼 금융산업