
구글이 13일(현지시각) 기술 블로그에 '특정 음성 인식기술'을 공개했다. 소음이 많거나 여러 명이 대화하고 있는 환경에서 특정 인물의 음성만 분리·인식하는 기술이다.
구글은 이 기술을 개발하기 위해 유튜브에 등록된 10만개쯤의 동영상을 활용, 사람이 대화할 때의 입 모양과 음성을 추출했다. 이어 특정 인물의 얼굴과 목소리를 파악할 수 있도록 신경망 네트워크를 훈련시켰다.
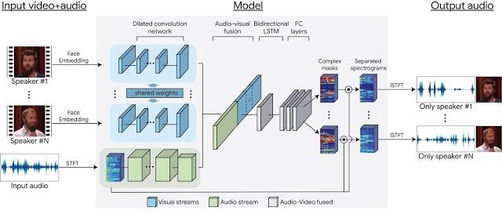
구글은 이 기술이 동영상 속 특정 인물의 음성을 인식, 증폭하는 것 외에 여러 분야에 응용 가능하다고 밝혔다. 화상 회의, 보청기 등이 예시다.
이 기술은 입 모양을 인식하면 발음을 더 정확히 파악할 수 있는 덕분에 유튜브 자동 번역 기능의 성능을 높여줄 전망이다.