
소프트웨어 전문지 마이크로소프트웨어 395호는 데이터과학을 주제로 담았습니다. 데이터과학에 대한 개론, 학습 방법, 실무 적용 사례, 학계 등 마소 395호 주요 기사들을 IT조선 독자에게도 소개합니다. [편집자주]
국내에서나 해외에서나 데이터 사이언스는 큰 화제다. 그동안 쓰레기 더미로 치부하던 데이터를 이용해 자동으로 의미를 찾거나 최적화하고, 비약적인 퍼포먼스 향상이나 수익을 낼 수 있는 일을 한다는 것이 마법과 같아서일 것이다. 실제로 월스트리트로 대표되는 금융업계에 데이터 사이언스와 인공지능 관련 직업이 비약적으로 늘어났다. 반면, 기존 월스트리트를 대표하던 ‘트레이더’, ‘퀀트’ 등은 하향세를 면치 못하고 있다.
퀀트는 금융의 여러 분야 중 투자와 자산관리 측면에서 가장 많은 활약을 했다. 주가가 어떻게 변하는지 분석했고, 통계적으로 어떤 요인이 주가에 영향을 미치는지 분석해 가장 영향을 많이 주는 요인을 모아서 팩터 모델이라 명명했다. 퀀트는 주가에 아직 반영되지 않은 재무 데이터를 미리 파악해, 주가에 반영되기를 기다리면서 이익을 얻었다.
그러던 중 컴퓨팅 파워 증가로 새로운 형태의 퀀트가 등장했다. 주문 빅데이터를 이용해 이익을 얻는 퀀트다. 기존 재무 데이터는 비교적 용량도 적고 복잡하지 않았지만, 주문 데이터는 시장 참여자가 주문을 내고 취소하거나 변형적인 주문을 내는 것을 모두 기록했다. 그 때문에 데이터 규모도 어마어마했고 노이즈도 심했다. 하지만 컴퓨터 성능이 비약적으로 증가하고 통계 분석 툴의 진화 덕분에 주문 데이터를 이용한 퀀트가 2010년경부터 많은 활약을 시작했다. 이들의 수익은 어마어마해서 대학에서 앞다퉈 퀀트를 양성하는 금융공학 과정을 만들었다. 투자 은행이나 헤지펀드에서는 통계학과 컴퓨터 공학을 공부한 퀀트를 대거 영입하기 시작했다.
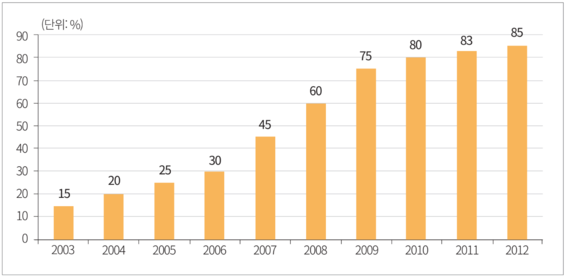
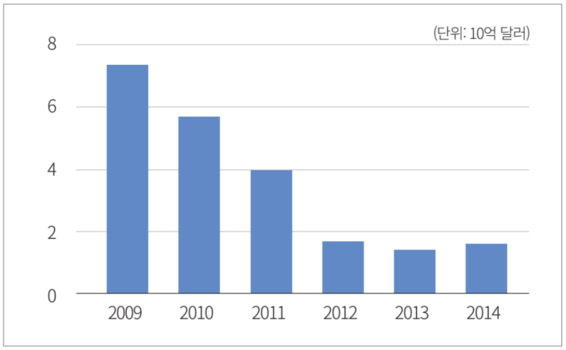
권용진 필자의 ‘금융업계에 부는 데이터 사이언스 바람’에 대한 자세한 내용은 ‘마이크로소프트웨어 395호(https://www.imaso.co.kr/archives/4654)’에서 확인할 수 있다.