
소프트웨어 전문지 마이크로소프트웨어 395호는 데이터과학을 주제로 담았습니다. 데이터과학에 대한 개론, 학습 방법, 실무 적용 사례, 학계 등 마소 395호 주요 기사들을 IT조선 독자에게도 소개합니다. [편집자주]
데이터 사이언스는 데이터로부터 의미 있는 정보를 찾기 위한 일련의 과정 및 기술을 포괄하는 개념이며, 그 핵심에는 머신러닝이 있다. 데이터를 수집하고 적절한 전처리를 거친 뒤, 데이터로부터 패턴을 발견해 예측 등에 활용한다. 이런 패턴 발견을 가능하게 하는 것이 바로 머신러닝이다.
머신러닝은 학문 분야로써 이에 속하는 다양한 기법이 존재한다. 기본적으로 수학적, 통계적 수식으로 표현된 모델이 하나의 기법을 이룬다. 수식은 주어진 데이터를 반영해 구성되며, 학습을 통해 수식에서 알려지지 않은 값인 모수를 계속 업데이트해 최종적으로 완성된 모델을 만든다. 학습이 끝난 수식에 새로운 데이터 샘플을 입력해 그에 맞는 예측을 하거나, 학습된 모수를 이용해 기존 데이터에 대한 의미 있는 정보를 제공한다.
머신러닝에는 다양한 기술이 존재하지만, 현재 가장 관심을 받는 것은 역시 인공 신경망 기반 딥러닝 기법이다. 딥러닝은 인공지능 모든 분야에 있어 독보적인 성과를 내고 있으며, 그중에서도 이미지 데이터 분석에 필수적으로 쓰인다.
인공 신경망 일종인 합성곱 신경망(Convolutional Neural Networks, CNNs)은 대부분 이미지 분석에 기본적으로 사용되며, 세부 목적에 따라 변형되고 다른 기법과 조합하면서 계속 발전하고 있다.
딥러닝의 성과와 함께 대두되는 문제 중 하나는 이렇게 학습된 인공 신경망을 ‘어떻게 사람이 이해할 수 있도록 해석할 것인가?’다. 다른 머신러닝 기술 대부분과 마찬가지로 인공 신경망 모델 자체만으로는 예측한 결과의 근거를 사람에게 논리적으로 설명하기 어렵다. 학습된 모수가 수식 내부에서 서로 연계돼 계산에 사용됨으로써 최적의 예측을 하므로 입력과 출력을 명확한 인과 관계로 표현할 수 없기 때문이다.
최근 이런 문제를 해결하기 위해 다양한 방식이 시도되고 있으며, CNN 기반 인공 신경망을 해석하려는 방법의 하나가 바로 특징 시각화(Feature visualization)다. 특징 시각화를 통해 신경망 각 뉴런에 해당하는 대표 이미지를 시각화할 수 있으며, 학습된 모델이 단계마다 이미지를 어떻게 필터링해 최종적으로 적합한 예측을 수행하는지 사람이 이해할 수 있도록 표현해준다.
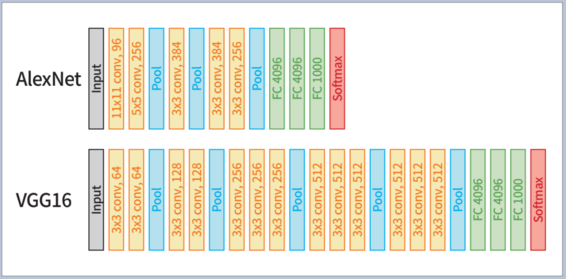
이후 이를 발전시켜 신경망 구조를 다양하게 변화시킨 다른 여러 네트워크가 제안됐다. ‘VGG-16’은 여덟 개였던 알렉스넷 신경망 층을 16개로 확장하고 구조를 약간 변형해 성능을 높였으며, 구글넷(GoogLeNet)은 인셉션 모듈이라는 방법을 제안해 오류를 6.7%까지 낮췄다.
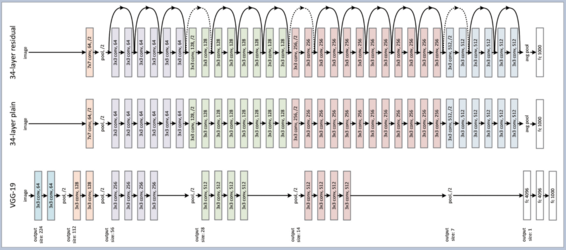
2015년 ILSVRC에서 발표돼 1위를 차지한 ResNet(Residual neural network)은 152개 층을 보유하고 있으나, ‘skip connections’라는 새로운 구조를 적용함으로써 계산 복잡도는 오히려 이전 모델보다 낮아지는 성과를 보였다. 또한 ‘top-5’ 오류를 3.6%로 낮추며 사람이 분류하는 것보다 더 좋은 성능을 획득했다.
CNN 기반 모델은 이미지 분류뿐 아니라 다양한 컴퓨터 비전 작업에 적용돼 좋은 성과를 내고 있다. 이미지 쿼리를 사용한 검색(Image retrieval), 이미지상 객체 위치와 레이블을 예측하는 객체 검출(Object detection), 이미지 영역을 분리해 레이블링하는 이미지 분할(Image segmentation), 사람의 움직임을 검출해 자세를 알려주는 자세 추정(Pose estimation) 등이 주요 분야다.
이미지를 특징 레벨에서 분석하는 것은 다양하게 활용될 수 있다. 이미 좋은 성과를 보이는 스타일 전이뿐 아니라 특징 기반의 이미지 검색, 신경망 기반 예술적 이미지 생성 등 앞으로 지금까지 적극적으로 활용되지 않았던 분야에서 많은 발전이 있으리라 기대한다.
김영민 필자의 ‘이미지 데이터 분석의 특징 시각화와 스타일 전이’에 대한 자세한 내용은 ‘마이크로소프트웨어 395호(https://www.imaso.co.kr/archives/4654)’에서 확인할 수 있다.