
소프트웨어 전문지 마이크로소프트웨어 395호는 데이터과학을 주제로 담았습니다. 데이터과학에 대한 개론, 학습 방법, 실무 적용 사례, 학계 등 마소 395호 주요 기사들을 IT조선 독자에게도 소개합니다. [편집자주]
MMORPG는 다양한 유저가 동시에 플레이하는 장르다. 유저 대신 게임을 하도록 만들어진 일종의 자동화 프로그램인 봇은 게임의 쾌적한 플레이를 방해하는 요소가 된다. 열심히 플레이한 유저에게 상대적 박탈감을 줄 뿐 아니라, 게임 내 콘텐츠 소모 속도가 증가해 운영에 어려움을 주는 등 다양한 문제를 야기한다. 그래서 엔씨소프트 데이터분석팀은 봇 유입에 대한 흐름이나 유저의 주력 콘텐츠 등을 파악해 게임 운영 및 기획에 편의를 제공하기 위해, 각 게임마다 유저의 행동 특성으로 플레이 성향에 따라 그룹을 분류하는 클러스터링 분석을 진행해왔다.
하지만 게임이라는 특징에 따라 업데이트나 이벤트가 생기면 콘텐츠가 급격하게 변화한다. 콘텐츠의 급변은 클러스터링 분석 모델의 노후화를 일으켜, 이를 개선해야 하는 문제가 빈번히 발생한다. 모델을 생성하기 위해서는 많은 자원이 필요하다. 운영 관련 부서와 지속적인 논의를 통해 특성(Feature)을 선정하고 데이터를 여러 방식으로 가공해야 분석을 위한 머신러닝 알고리즘에 초기 입력 데이터로 사용할 수 있다. 이때, 모델을 생성하기 위해서는 데이터 가공 과정을 수동으로 진행해야 한다. 이런 과정을 특성 공학(Feature Engineering)이라 하며, 수동으로 진행하기 때문에 탐사 분석에 소모되는 작업 시간이 오래 걸리고 즉각적인 특성 추가에는 어려움이 따른다.
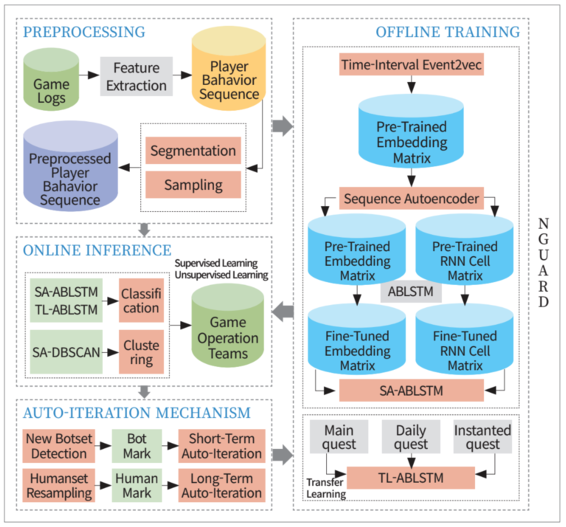
‘학습 데이터나 혹은 탐지를 하려는 목적 데이터를 준비하는 과정인 데이터 전처리 과정’, ‘실질적인 딥러닝 알고리즘이 들어가는 구간인 학습 과정’, ‘예측한 결과를 제공하는 추론 과정’, ‘학습 데이터와 모델을 갱신하는 과정인 자동 반복 과정’으로 구성돼 있다.
두 번째는 학습 과정이다. 학습 과정은 크게 선행 학습 과정과 분류 모델링 과정으로 나뉜다. 선행 학습 과정은 임베딩 및 초기 가중치 설정을 위해 진행된다. 이 논문에서는 유저가 수행한 각각의 퀘스트를 벡터 형태로 임베딩 하기 위해 워드투벡터(Word2Vec)를 활용했다. 이때 "유저가 수행한 퀘스트 사이의 시간 간격"을 초기 가중치로 활용한 점에 주목해야 한다.
이 임베딩 벡터를 이용하면 각 유저별 퀘스트 수행 이력에 대한 시퀀스 매트릭스를 생성할 수 있다. 그 후 시퀀스투시퀀스(Seq2Seq) 알고리즘으로 각 유저의 시퀀스 패턴을 학습한다. 이 학습 과정을 통해 얻은 인코더의 가중치는 뒤에서 설명할 최종 분류 모델 학습 시 초기값으로 활용한다. 또한 분류 모델링 과정에서는 시퀀스 데이터뿐 아니라 몇 가지 통계 데이터를 함께 활용한다.
세 번째는 최종 모델까지 학습을 완료하면 실제 결과를 전달하는 추론 과정이다. 추론 과정에서는 실제 제재(Block)를 담당하는 운영팀에게 봇 확률 정보를 웹 서비스로 전달을 하거나 비지도 학습 결과로 군집화를 진행해 학습 모델에서 출력된 봇 확률을 함께 제공한다. 제대로 분류되지 않은 유저는 피드백을 받아 추후에 정답 집합을 구축할 때 갱신할 수 있다.
마지막인 자동 반복 과정은 새로운 봇 패턴을 발견하거나 기존 봇 활동 패턴에 변화가 있으면, 해당 데이터를 반영해 모델 및 정답 집합을 갱신하는 과정이다.
우리는 이 논문에서 제안한 프레임워크를 우리 상황을 반영해 구현했다. 우리가 구현한 모델과 논문에서 제안한 내용의 가장 큰 차이점은 학습에 사용한 활동 정보의 종류이다. 논문에서는 유저가 수행한 퀘스트 이력만 학습에 사용했지만, 우리는 유저가 게임 내에서 수행한 대부분의 행동을 사용했다. 이를 통해 더 정교한 유저의 행동 패턴을 학습할 수 있을 것이라 기대했다.
강병수, 서상덕, 안진옥 필자의 ‘게임 로그를 활용한 봇 분류 모델’에 대한 자세한 내용은 ‘마이크로소프트웨어 395호(https://www.imaso.co.kr/archives/4654)’에서 확인할 수 있다.