
구글이 기존 머신러닝 기법을 버리고 새로운 기법을 도입했다. 이는 과거 중앙화된 클라우드 시스템이 필요했던 것과는 다르다. 모바일에서 스스로 데이터로 학습을 한다. 중앙 서버는 새로운 알고리즘을 모바일에 전달한다. 마치 사람이 자는 동안 꿈을 꾸며 배운 것을 복습하다가, 깨어있을 땐 새로운 내용을 습득하게 되는 것과 유사하다.
블레이즈 아게라 이 아카스 구글 디스팅귀시드 사이언티스트(Distinguished Scientist)는 22일 서울 중구 프레스센터에서 구글의 연합학습 개념을 소개했다.
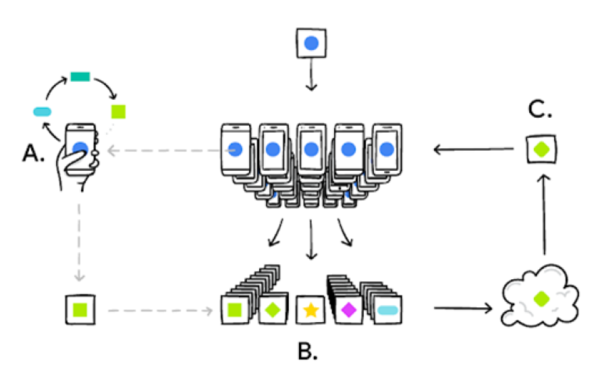
AI가 발전하기 위해서는 더 많은 데이터로 학습을 해야한다. 이때 일반적으로는 엣지 단에서 수집한 데이터를 중앙 서버로 전송한 뒤 중앙 서버가 데이터를 분석한 후 다시 그 결과를 엣지 단으로 보내주는 과정이 필요했다.
문제는 이 과정에서 과부하가 걸린다. 한계가 발생한 이유다. 클라우드 서비스가 보편화되면서 클라우드가 처리해야 할 용량도 급속도로 늘어났다. 이 때문에 수집한 데이터를 분석하고 송신하는 과정에 지연 현상도 발생한다. 클라우드로 각종 데이터가 몰리면 보안 문제도 피할 수 없다.
구글은 여기에서 연합학습을 고안했다. 연합학습은 기기 내에서 사용자가 입력하는 데이터를 기반으로 스스로 학습해 AI 모델을 발전시킨다. 원본 데이터는 기기 내에 그대로 남고 학습된 모델만 서버에 올라간다. 또 연합학습이 적용된 기기는 서버에 접속되지 않았을 때는 이전에 받은 알고리즘으로만 머신러닝이 구동된다. 이후 무료 와이파이에 연결되면 서버에서 새 알고리즘을 받는다.
아카스 사이언티스트는 "마치 사람이 자는 동안 꿈을 꾸며 배운 것을 복습하다가, 깨어있을 땐 새로운 내용을 습득하게 되는 것과 유사하다"고 설명했다.
현재 구글은 구글 키보드인 지보드(Gboard)에서 연합학습을 활용한다. 지보드가 이용자에게 특정 검색어를 추천하면 이용자는 이를 선택할 수 있다. 클릭여부는 이용자 몫이다. 스마트폰은 현재 이용자 활용 환경 정보와 이용자가 이 제안을 실제로 사용했는지 여부를 함께 저장한다.
이처럼 스마트폰에 이용자 활용 기록이 쌓이면 이것이 학습 데이터가 된다. 이용자 맞춤형으로 똑똑해진 AI 덕분에 이용자는 구글에서 더 최적화된 서비스를 이용할 수 있게 된다.
머신러닝 모델이 구글 서버에 업로드 되는 과정에서 이용자 데이터가 유출되는 문제는 없을까.
블레이즈 아게라 이 아카스 사이언티스트는 "이용자 데이터를 기반으로 머신러닝 모델이 학습되지만, 이용자 데이터가 아닌 학습된 AI 모델만 구글 서버에 올라간다"며 "개별 업데이트 정보가 클라우드에 저장되지는 않는다"고 설명했다. 또한 연합학습에는 이용자 경험에 부정적인 영향을 미치지 않는 경우에만 참여한다.
블레이즈 아게라 이 아카스 사이언티스트는 "연합학습은 프라이버시를 보장하는 동시에 스마트폰에서 개선된 머신러닝 모델을 즉시 이용할 수 있게 된다"고 설명했다.