
소프트웨어 전문지 마이크로소프트웨어 395호는 데이터과학을 주제로 담았습니다. 데이터과학에 대한 개론, 학습 방법, 실무 적용 사례, 학계 등 마소 395호 주요 기사들을 IT조선 독자에게도 소개합니다. [편집자주]
AI 네트워크는 개발자, 자원 제공자, 서비스 사용자를 다양한 데이터를 활용한 대용량 머신러닝과 연결해주는 네트워크다. 서로 다른 참여자와 여러 서비스가 네트워크상에서 혼존하기 때문에 AI 네트워크에서는 개인 정보 보호 문제와 보안 문제에 특히 주의해야 한다. 개인 정보 보호는 특정한 방법만 사용해서 이뤄지지 않는다. 데이터를 수집하는 시점부터 거래할 때, 활용할 때, 만든 결과를 제공할 때 등 항상 염두에 둬야 한다.
머신러닝과 개인 정보 보호에 대해 활발한 연구가 이뤄지고 있지만, 실무에서는 개인 정보 보호까지 신경 쓰기에는 물리적 시간이 부족하다. 특히 개인 정보 보호에 대해 개념이 잘 잡혀있는 대기업의 경우 머신러닝에서 사용하는 데이터와 알고리즘에 각종 정책이 적용된다. 하지만 스타트업이나 개인 개발자는 이를 신경 쓰기가 쉽지 않다.
개발자의 개인 정보 보호 기술에 대한 인식도 제각각이다. 각종 머신러닝 기법을 열심히 공부한 것에 비해 개인 정보 문제에는 경험이 없는 개발자가 있는가 하면, 어떤 개발자는 이론으로 배웠지만, 실무에 필수적으로 적용해야 하는지 의문을 품기도 한다. 관련 자료와 논문을 검색해보면 어느 정도 정형화된 자료가 있지만, 상황에 따라 쉽게 개념을 이해해서 바로 적용할 수 있는 코드를 찾기가 쉽지 않다.
먼저 머신러닝을 간단히 설명하면, 가지고 있는 데이터로 훈련(Training) 후 앞으로 들어올 데이터를 예측(Prediction)하는 과정이다. 예측은 훈련된 모델을 사용한다. 훈련 시 사용된 데이터가 모델에 반영되므로, 만약 데이터에 개인 정보가 들어있었다면 모델에도 어느 정도 반영된다.
따라서 어느 정도의 데이터를 모델에 담아야 특정 사용자의 정보임을 알 수 없게 만들 수 있을지가 보안에서 기본 출발점이라고 할 수 있다.
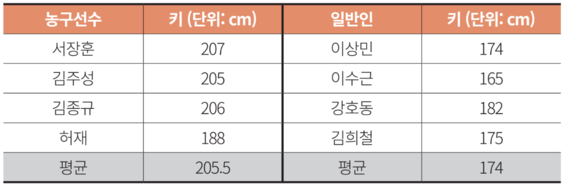
위 그림 데이터로 만든 모델에 따르면 유재석(178cm)은 일반인 평균에 가깝기 때문에 ‘일반인’, 현주엽(196cm)은 ‘농구선수’로 예측할 수 있다.
키가 정확히 207cm인 한국 농구 선수는 몇 없을 것이기 때문에, 키 데이터로부터 서장훈임을 유추할 가능성이 있다. 이를 위해 사용할 수 있는 간단한 방법으로 버킷팅(Bucketing)이 있다.
버킷팅은 정확한 값을 사용하는 대신 의미를 잃지 않는 범위의 대표 값을 사용하는 것이다. 예를 들어 5cm 단위로 버킷팅을 하면 서장훈, 김주성, 김종규의 키는 205cm, 허재의 키는 190cm로 기록해 키로부터 사람을 알아내기가 더욱 어려워진다.
버킷팅은 너무 큰 값을 선택하면 의미 있는 트레이닝을 할 수 없고, 너무 작은 값을 선택하면 사용자를 유추할 수 있다. 특히 설문 조사 값이나 시험 결과 값에서도 이런 상황은 많이 발생한다. 수능 점수별로 학생 특성을 파악하고 싶다면, 수능 점수를 그대로 사용하는 것보다 점수를 특정 단위로 쪼개서 버킷팅 하는 것이 좋다.
버킷팅을 할 때 또 주의할 점은 아웃라이어(Outlier)의 존재다. 예를 들어 1등과 2등 점수 차가 50점일 경우, 50점 이상의 버킷팅을 하지 않으면 1등과 2등의 데이터 사용 여부를 구분할 수 있다. 의미 있는 단위의 버킷팅을 하지 못하면, 트레이닝 된 모델도 정확도가 떨어진다. 아웃라이어의 존재는 모델을 공개할 때도 조심해야 한다. 예를 들어 최홍만(220cm)이 ‘일반인’에 있다면, 평균 키는 183.2cm로 급상승해 평균만으로도 최홍만의 존재를 유추할 수 있다.
정리하면 데이터가 적을수록 그리고 특정 개인의 데이터가 대표 값과 멀어질수록 개인 정보를 유추하기 쉽다. 그렇다면 각 버킷마다 충분한 양의 데이터가 있는 경우는 문제없을까?
또 하나 주목할 요소는 데이터를 가져온 모집단에 대한 존재가 바깥세상에 어느 정도 공개돼 있는지다. 위 예제에서 농구선수는 한국 농구선수 데이터를 사용했으므로, 한국 농구선수 중 207cm를 찾았을 때 서장훈 선수임을 알기가 쉬웠다. 반면, 농구 선수가 아닌 사람이 전 국민 중 랜덤으로 추출한 데이터라면 키 데이터만으로 특정 사람을 지목하기는 쉽지 않을 것이다. 즉, 트레이닝 데이터에 나와 있지 않은 추가 정보(Side Information)의 존재 또한 굉장히 중요한 요소다.
요즘처럼 검색이 발달한 시대에는 많은 경우에 추가 정보를 확보할 수 있다. 유명한 예로 넷플릭스 프라이즈(Netflix Prize) 데이터로 개인 정보가 유출된 적이 있다. 관련 논문은 ‘Robust De-anonymization of Large Sparse Datasets(Narayanan & Shmatikov, 2008)’로, 넷플릭스 프라이즈 데이터에 ‘IMDb(Internet Movie Database)’ 데이터를 활용하면 사용자를 식별(De-Anonymization)하는 것이 어렵지 않음을 보여줬다.
인터넷에는 개인을 알아낼 수 있는 정보가 많다. ‘IMDb’ 같이 넷플릭스와 연관성이 강한 데이터를 사용할 경우, 데이터에서 제거한 개인 식별자를 적은 데이터만으로도 알아낼 수 있다. 당시 넷플릭스 데이터는 전체 데이터의 표본만 공개해 안전하다고 주장했는데, 실험 결과별로 도움이 안 되는 것으로 나타났다.
신경망 기반 머신러닝 기술은 다양한 영역에서 놀라운 성과를 거뒀지만, 빠르게 발전한 만큼 개인 정보 보호 영역에서는 허점이 많다고 생각한다. 과거에는 직감적, 논리적으로 규정할 수 있었던 개인 정보 보호 영역이 무수히 많은 가중치로 이뤄진 신경망에서는 최종적으로 나오는 모델의 특성을 사람이 파악하기가 어려우므로, 개인 정보가 어느 정도로 보호됐는지의 지표를 잘 갖추는 것이 중요하다.
데이터 세트를 모으기 위해 여러 관계자를 거칠 때도 각 단계에서 민감한 개인 정보에 대해 항상 유의한다면, 모델 품질을 유지하며 효율적인 모델을 만들 수 있을 것이다.
데이터 수집 단계부터 트레이닝까지 개인 정보는 항상 머리 속에 염두에 둬야 한다. 꼭 대기업에서만 필요한 것이 아니라 아무리 작은 데이터라도 수집할 때는 수학적으로 어느 정도 개인 정보의 위험성이 있는지 인지하고 있어야 할 것이다.
김민현 필자의 ‘AI 네트워크에서 개인 정보 보호와 보안’에 대한 자세한 내용은 ‘마이크로소프트웨어 395호(https://www.imaso.co.kr/archives/4654)’에서 확인할 수 있다.