
지금까지 생성형 인공지능(AI)으로는 무음의 동영상만 제작할 수 있었으나, 이를 해결할 수 있는 기술이 등장했다. 구글의 AI 연구소 딥마인드는 동영상용 사운드트랙을 생성하는 AI 기술을 개발하고 있다고 밝혔다.
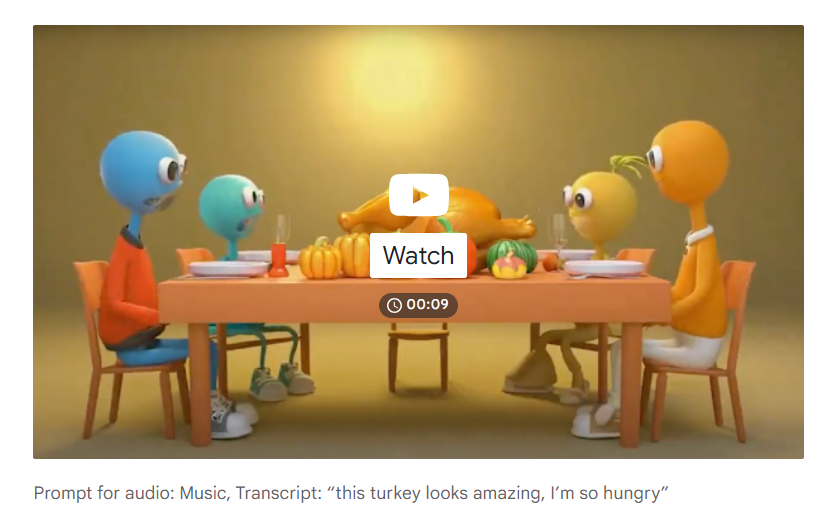
17일(현지시각) IT매체 테크크런치에 따르면 딥마인드는 V2A(video-to-audio)라는 기술을 기반으로 이를 개발하고 있다. 딥마인드의 V2A 기술은 비디오에 맞는 오디오(음악, 음향 효과, 등장인물 목소리 등)를 생성하고 딥마인드의 딥페이크 방지 기술로 워터마킹을 표시하는 기술이다.
딥마인드에 따르면 V2A를 구동하는 AI 모델은 비디오 영상과, 소리, 대본 등을 조합해 학습됐다. 딥마인드는 "해당 모델은 비디오, 오디오 및 추가 주석에 대한 학습을 통해 특정 오디오를 비디오의 다양한 시각적 장면과 연결하는 방법을 학습한다"라고 말했다. 또한 딥마인드는 V2A 기술이 비디오의 원시 픽셀을 이해하고 생성된 오디오를 자동으로 비디오와 동기화할 수 있다는 강점을 가진다고 말했다. 다만 딥마인드는 현재 V2A는 완벽하지 않기에 당분간은 이 기술을 대중에게 공개하지 않고 피드백을 반영한 지속적인 연구 개발에 매진하겠다고 덧붙였다.
테크크런치는 이와 관련해 현재까지 생성형 AI가 제작한 동영상에는 오디오가 포함되지 않고 있다는 점에서, 딥마인드의 새로운 기술은 영화를 비롯한 미디어 시장에 큰 영향을 줄 것이란 전망을 제시했다.
홍주연 기자 jyhong@chosunbiz.com
관련기사